|
|
|
|
|
|
|
ABBYY FlexiCapture 是数据采集和文件处理的解决方案,组织可以用它自动化他们文件驱动的业务流程。它取代手动和昂贵的数据输入,提供全方位文件类型(如申请表格识别、索赔和秩序的文件识别、合同和票据数字化)的智能和准确的数据提取(ICR)。用泰比(ABBYY)FlexiCapture可扩展性,组织可以处理几乎任何数量,以及自动分类、分开、索引、把数据提取到后端应用程序中为了提高响应能力和随今天的不断提高交易速度的要求并进。
如何运作
泰比 (ABBYY) FlexiCapture一个非常智能,准确和可扩展的数据和文档捕捉软件 。它提供了一个单一的输入点,自动将任何结构和复杂性的文档变成可用性和可访问的数据,并输出到您的商业应用。泰比 (ABBYY) FlexiCapture将时间和资源消耗的人力输入模式变成了自动文档分割、分类和数据提取。
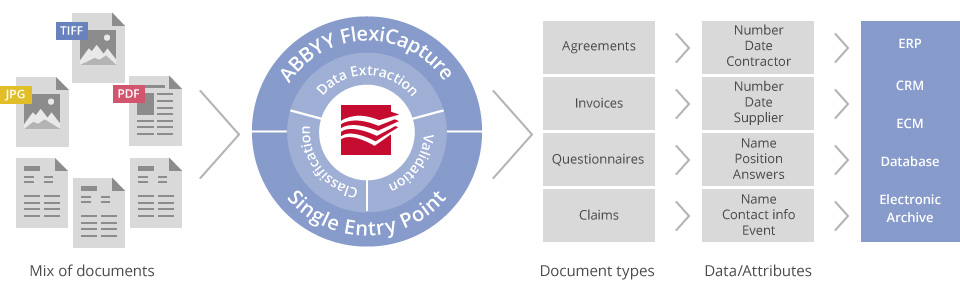
泰比 (ABBYY) FlexiCapture可以处理任何大容量各类型的文件
固定形式(问卷,调查,测试,纳税申报,及应用表格);
半结构化文档(发票,采购订单,效益解释和收据);
非结构化文档(合同,信件和文章)。
经过4个主要阶段(输入,识别,校验和输出),因此它们分类,识别,校验然后转成可靠,准确,可搜索和高度结构化的电子数据,进而加速相关部门和企业的商业处理流程。
泰比 (ABBYY) FlexiCapture提供了强大的设置工具和灵活的处理流程,来完成任何复杂的文件处理任务。
主要特点
通过自动数据输入软件加快数据输入业务流程,消除由于人力录入造成的时间和资源浪费。聪明的捕获算法使系统能够处理任何类型的商业文件,包括发票,协议,采购订单,登记表等等。

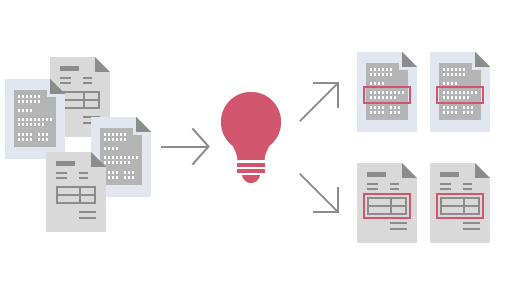
该软件采用人工智能算法按照自动分类和数据提取的目的来分析相关文档。泰比 (ABBYY) FlexiCapture可依据图像样本进行交互训练,以提供进一步的生产加工水平。
嵌入了泰比(ABBYY)获奖的识别和分类技术,并提供内置的验证规则,FlexiCapture保证了数据的异常高的准确性。符合人体工程学的校验问题的数据接口,允许另外的敏感性和有疑问数据的校验。
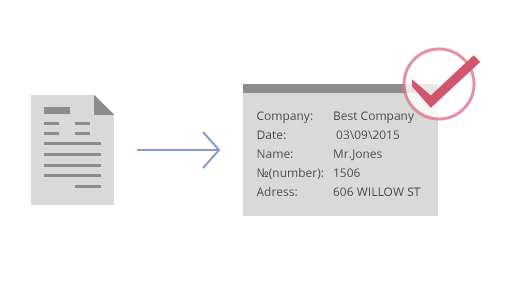
FlexiCapture文档采集解决方案提供了独立的和分布式的安装,并提供它们之间的完全兼容。这使得中小型企业可以在初始阶段采用简单和合理的模式来起步,并随着您公司业务的发展而不断扩展你的数据和文档处理环境。
如果你需要人工数据校验,可以使用基于Web的客户端,有效地分配你的员工,降低成本。
国际企业可能会受益于使用一种解决方案来处理多种语言的文件,包括中文,日文,韩文,越南语等180种!
先进的基于服务器的架构可以有效处理日常业务,而没有页数限制。该系统核心是功能强大的处理服务器,可以承担一切资源密集型操作,并执行自动化任务之间分配平衡的处理站和负载。微软集群支持,确保一致的系统运作,并防止系统故障数据损失的案件。
采取灵活的处理工作流程的优势,可以轻松地调整您的具体业务。泰比 (ABBYY) FlexiCapture提供了一个强大的工具,可以根据客户处理的阶段、脚本和外部模块修改基本文件处理的工作。
工作流还可以在无人参与模式的情况下处理文档。
在输入点就开始实现数据捕捉,降低纸张发送和存储的成本和额外环节。按需扫描可从任何地点和任何计算机远程执行,操作者在网页上只需点击一个web页面就安装了扫描客户端。
由于消除了劳动密集型操作,保证了快速投资回报,与此同时,瘦客户端和易于配置的文件分类和提取也确保了客户较低的总拥有成本。
友好的用户界面使操作者工作舒适而且有效。
最新功能

作为标准校验站的一部分,FlexiCapture现在提供脚本工具定制用户界面。这一新功能对于那些需要额外工具的项目或者监控有一些特殊的规则的项目是非常理想的。不论需求是修改菜单和工具栏,增加文档特殊功能增加控制,或者为了适应某一特殊场景而修改站点属性,这些都可以在FlexiCapture编写脚本实现。
强劲的扫描站可以下载,只需轻轻点击安装,在数秒钟之内就可以开始操作。按需扫描远程从任何计算机上的任何位置执行,操作者只需在网页上通过简单地点击一个链接安装就可以运行扫描站。安装完全自动化,并且不需要在客户端计算机有管理权限。扫描配置文件可以在本地进行管理或由操作员从中央服务器操作。

增加了通过电子邮件发送文件捕捉图像数据功能。 通过集成新的Microsoft Exchange服务器和POP3邮件服务器,图像文件可以作为邮件附件来处理。 您可以使用任意具有电子邮件功能的多功能办公设备或简单的发送一个预扫描文档到指定的电子邮件地址处理。
FlexiCapture可以满足你业务不断扩展的需要。借助FlexiCapture 新的先进体系结构,通过使用多核处理技术,它可以从数百万页的文档中提取数据。
借助于Microsoft ®群集服务器支持,FlexiCapture提供一个卓越的容错架构。基于服务器的系统组件可以安装在负载平衡和高可用性群集节点,确保稳定的系统运行,消除瓶颈,防止因为系统故障而造成数据损失。
FlexiCapture提供新的工具使业务流程的整合更容易。现在,标准的工作流程可据客户独特需求来客户化定制,以适应各种情况。FlexiCapture提供了强大的工具来整合用户的系统和外部模块,使用脚本定制工作流程。工作流也可以被扩展以适应不同的任务,如通过第三引擎加强图像质量,连接一个可选的OCR / ICR引擎,添加新的验证阶段和自定义文档路由。对.NET的支持进一步简化了客户模块和系统的集成。
FlexiCapture提供基于web的友好的用户数据校验界面,客户可从任何地方随时随地使用网络浏览器来进行访问。基于Web的数据校验站,无须安装。一旦开始处理文件,操作员只需要根据链接和登录就可以取得任务。
FlexiCapture引入了新的自动学习功能,可以简化文件的分类和模板创建,这样在实施阶段节省了时间。
有了这个新功能,一个简单的“指向并点击” 可用于创建布局的描述和定义文件类型进行分类:
-通过对一些要数据捕捉的图片上的参考点和数据区域进行一些训练,简单的布局描述可以自动生成。 此外,描述可通过人工增强,涵盖范围更广的文档布局类型。
-文档分类和分割,现在可以自动通过培训建立一个图像集。
最关键业务数据的字段可以由2个操作员校验,排除程序造成的或者人为造成的错误。数据只有在被2个操作员验证后才会被系统所接受。
新的自定义操作性能监视和报表系统,现已在FlexiCapture已经提供支持。水晶报表编辑器可让管理员生成由FlexiCapture数据库直接产生的用户报告。
FlexiCapture设计空白固定形式从未如此简单。新的向导指导你自动设计所有繁琐的必要步骤,如复选标记 数据合并配置文件可以合并条形码和图像,使大容量的工作自动化运作成为可能。更多的色彩选择,易于使用的默认设置,拖放多页的支持以及其它更多的功能为表单设计提供了更容易的方式。
京ICP备09015132号-996 | 网络文化经营许可证京网文[2017]4225-497号 | 违法和不良信息举报电话:4006561155
© Copyright 2000-2023 北京哲想软件有限公司版权所有 | 地址:北京市海淀区西三环北路50号豪柏大厦C2座11层1105室

















![网络文化经营许可证京网文[2017]4225-497号](/f/image/20180509/20180509164113_9707.jpg){kind=link}